🚨 주의! 여기서 비교하는 두 SQL 문은 비슷해 보이지만 같은 목적의 쿼리가 아닙니다.
- 첫 번째 SQL 문: 급여가 5000이 아닌 사원의 이름, 급여 표시
- 두 번째 SQL 문: 급여가 5000인 사원이 존재한다면 테이블 전체 미출력, 반대라면 전체 출력 // inner query에서 각 outer row에 대해 지정한 게 아님
EXPLAIN PLAN FOR
SELECT name, salary
FROM temp
WHERE salary <> 5000; -- TABLE ACCESS FULL(FULL SCAN)
EXPLAIN PLAN FOR
SELECT name, salary
FROM temp
WHERE NOT EXISTS (
SELECT 'X'
FROM temp
WHERE salary = 5000 -- INDEX_RANGE_SCAN
);
SELECT * FROM table(DBMS_XPLAN.DISPLAY);
쿼리를 실행할 때 인덱스를 활용하는지 아닌지를 크게 두 가지 방법으로 확인했다.
- GUI 아이콘 클릭
- 쿼리문 날리기
1. GUI 아이콘

위 사진에서 3번째 아이콘(원기둥에 뭐가 붙어있는 아이콘)에 커서를 두면 '계획 설명'이라는 말이 나온다. 인덱스 사용여부는 이 '실행 계획'을 통해 확인하는 것이다. 이를 실행하면 아래와 같은 결과가 나타난다.
이 SQL 문은 어떤 컬럼(>salary)의 값이 5000인 것을 찾기 위해 inner 절에서 IDX_SAL 인덱스를 활용해 RANGE SCAN을 한다. 서브 쿼리를 활용했기 때문에 외부 절, 내부 절이 구분되어 분석되었다. 옆의 카디널리티와 Cost를 참고하면 Index Scan이 효율적으로 사용됐음을 확인할 수 있다.
쿼리를 실행할 때 인덱스를 활용할 것인지 아닌지를 판단하는 것은 Optimizer다. where 절에서 비교 기준이 되는 컬럼이 인덱스로 있다고 해도 아래와 같은 이유 등으로 비효율적이라고 판단되면 Full Scan으로 처리될 수 있다.
cf. Optimizer는 SQL 문을 해석한 뒤 실행 계획을 세우고 그에 맞춰 명령을 생성한다. Optimizer가 자동으로 알아서 최적화된 방법을 찾는다고 해도 SQL 문을 잘 작성하고 실행 계획을 맞게 세우는 게 필요하다. 이게 곧 튜닝이다.
※ 인덱스를 만드는 경우
- 조건 절이나 조인 조건에서 컬럼을 자주 이용할 때
- 컬럼이 넓은 범위의 값을 가질 때
- 많은 NULL 값을 갖는 컬럼일 때
- 테이블의 데이터가 많고 그 테이블에서 조회되는 행의 수가 전체의 10-15%일 때 (소량 검색에 유리)
※ 인덱스가 있지만 사용되지 않는 경우
- 인덱스 컬럼이 비교되기 전에 변형이 일어난 경우
- 부정(NOT, <>)으로 조건을 기술한 경우
- 인덱스 컬럼이 NULL로 비교할 경우 (컬럼의 값이 NULL인 행은 인덱스에 저장되지 않음)
- Optimizer의 취사 선택 (= 만들었다고 꼭 쓰는 게 아니다)
※ 인덱스를 만들지 않아야 할 때
- 테이블이 작을 때
- 컬림이 조회의 조건으로 사용되는 경우가 별로 없을 때
- 대부분의 조회가 행의 10-15% 이상을 검색한다고 예상될 때
- 테이블이 자주 변경될 때
위 사항들을 이해했어도 실제로 쿼리를 돌려보지 않는 한 완벽한 이해가 불가능하단 걸 깨달았다. 그렇기 때문에 이제는 Index를 사용하겠지 싶어도 (초기 데이터량이 적어서) 계속 Full Scan으로 나올 때는 조금 당황했다. 데이터량이 적을 때는 처음부터 테이블을 빠르게 탐색해 나가는 게 더 효율적일 테니 Full Scan 처리를 한 것이다. 근데 데이터를 많이 많이 넣어주니까 인덱스를 활용했다. 데이터가 또 많다고 다 되는 것도 아니지만... 데이터는 아래처럼 재귀적으로 넣어 주었는데, 이때 주의할 점은 새로운 테이블에서는 초기 데이터를 먼저 넣어준 뒤 실행해야 된다는 점이다. (사실 당연한 말)
insert into temp (name, salary) -- ** 데이터가 충분히 커야 INDEX RANGE SCAN
(select name, salary from temp); -- 재귀적으로 2배씩 데이터 삽입
2. 쿼리 문 날리기
MySQL과 MariaDB에서는 실행 계획을 확인할 때 'EXPLAIN' 명령어만 앞에 붙이면 되는데 Oracle에서는 명령어 실행 과정이 조금 달랐다. MySQL(MariaDB)에서는 쿼리 문 앞에 EXPLAIN을 적어준 뒤 쿼리를 실행하면 바로 실행 계획이 뜬다.
Oracle에서는 EXPLAIN 만 적어주면 쿼리가 실행되지 않는다. EXPLAIN PLAN FOR 을 앞에 적어주어야 실행 계획이 만들어지는데 이 조차도 일단 '설명되었습니다.'의 메시지가 띄워질 뿐 달라지는 건 없었다.
이후에는 어떻게 출력해야할 지 몰라서 chatGPT한테 물어봤더니 이 명령문을 알려주었다 ^^!
explain plan for 쿼리문;
select * from table(DBMS_XPLAN.DISPLAY);
실행 계획을 여러 개 만들고 실행하면 가장 최근의 실행 계획을 보여주는 식이었다. 결과 화면은 첫 번째 방법과 크게 다르지 않았다. 인덱스를 단순히 사용했는지 아닌지를 확인하는 거면 버튼 하나 누르는 게 더 편할 듯 하다.
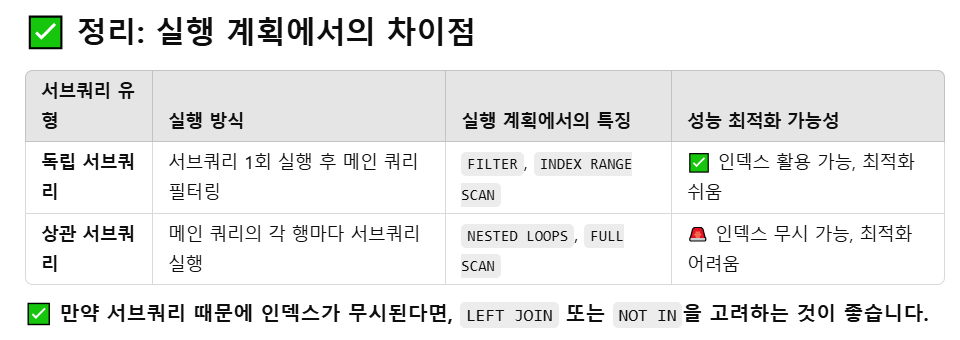
인덱스를 잘 활용하기 위해서는 조건 절에서 NOT을 분리해 본다. 위에서 SQL문을 처음 의도대로 작성하지 못 해서 아래 사진을 첨부한다. 시간은 걸렸지만 일반 쿼리와 서브쿼리, 그리고 독립 서브쿼리와 상관 쿼리와의 관계를 확인할 수 있었다.
- 비교 연산자는 NULL 값을 비교할 수 없어 결과 집합에 포함시키지 않는다. (chatGPT 참고)
- 비교 연산자(=, <>, !=, >, <, >=, <= )는 NULL 비교 불가
- NULL은 어떠한 값과도 비교될 수 없고, T/F가 아닌 UnKnown 결과를 반환
- where 절에서 UnKnown인 행은 자동으로 필터링 됨
그러면 상관 쿼리에서는 NULL 값이 어떻게 포함될 수 있었는가?
- EXISTS 서브쿼리가 NULL을 반환하는 경우도 TRUE가 아니니 해당하는 행이 없다고 간주되어서 NOT EXISTS가 TRUE로 처리
- 즉 UnKnown도 FALSE로 해석 - 3, 5번째처럼 서브 쿼리가 처음 한 번만 실행되는 독립 서브쿼리는 내부에서 INDEX RANGE SCAN 가능
- 4, 6번째처럼 서브 쿼리가 메인 쿼리의 행마다 실행되는 상관쿼리는 FULL SCAN 대상
- 각 행마다 서브 쿼리를 실행하기 때문에 INDEX 활용이 어려울 수 있다고 함 (chatGPT 참고)



'패스트캠퍼스 백엔드 부트캠프 3기 > database' 카테고리의 다른 글
| [database] 트리거 (Trigger) 생성 오류 해결 및 메시지 출력 (0) | 2025.02.08 |
|---|---|
| [database] 데이터베이스 목차 정리 (0) | 2025.02.07 |
| [database] Constraint (0) | 2025.02.03 |
| [database] SQL 용어 설명, 조인과 서브쿼리 (0) | 2025.02.03 |
| [database] 오라클 다중 insert 문 (1) | 2025.01.22 |