책 [Do it! 알고리즘 코딩 테스트 - 자바 편;김종관 지음]을 참고하여 작성하였습니다.
다익스트라(Dijkstra) 알고리즘
- 출발 노드와 모든 노드 간의 최단 거리 탐색 (출발 노드와 도착 노드, 두 노드만이 아님)
- 에지(가중치)는 모두 양수여야 한다
- 시간 복잡도는 O(E * logV)
- 그리디 알고리즘
- 접근 방법
- 그래프를 인접 행렬, 인접 리스트로 구현할 수 있지만 일반적인 경우에서 인접 리스트가 더 빠름, 하지만 상황에 따라 달라짐
- 인접 행렬 O(V^2) - 밀집 그래프에 유리, 연결 노드 확인하는 데 O(1)
- 인접 리스트 O(E * log V) - 희소 그래프에 유리, 연결 노드 확인하는 데 O(연결된 간선의 수) - 최단 거리 배열을 초기화 (최댓값으로 모두 채우기)
- 거리 배열에 출발 노드 인덱스에 0 대입
- 아직 방문하지 않은 노드 중 현재 거리 값이 가장 작은 노드를 선택
- 그러면 출발 노드를 먼저 방문하고 그와 연결된 노드 탐색 - 최단 거리 배열 업데이트 = Min(선택 노드의 배열 값 + 에지 가중치, 연결 노드의 배열 값) 이 과정을 반복

- 구현 방법
- 거리 값이 가장 작은 노드를 선택하기 위해 PriorityQueue 혹은 힙을 사용
- 노드 클래스를 만들어 (목적지)노드 값과 가중치 값을 저장
- 노드 간 비교할 때 가중치 값이 작은 노드를 선택하기 위해 Comparable 인터페이스로 비교 기준 설정
- 수행 과정
1. 그래프 배열, 방문 배열, 거리 배열을 생성한다.
1-1. 거리 배열은 최댓값(ex. Integer.MAX_VALUE)으로 초기화하고, 출발 노드 인덱스는 0을 넣는다.
1-2. 그래프 배열은 인접 리스트로 만들고, 배열은 노드 값과 가중치 값을 함께 저장하는(이하 노드 클래스) 배열로 한다.
(어떻게 구현하느냐에 따라 다르겠지만 책에 언급된 방식을 적용했습니다.)
2. 에지 정보를 그래프 배열에 저장한다. (대개 방향 그래프)
3. 노드 클래스(노드, 가중치)를 저장하는 우선 순위 큐를 만든다.
3-1. 노드 클래스는 Comparable 인터페이스를 구현하여 가중치 값을 기준으로 오름차순 시킨다 - 정렬된 큐의 맨 앞의 값 사용
4. 출발 노드를 우선 순위 큐에 넣는다. (거리는 0으로)
5. 큐에서 최단 거리를 가진 노드를 꺼내어 해당 노드의 인접 노드를 탐색한다.
6. 각 인접 노드 중 방문하지 않았으며, (선택 노드의 배열 값 + 에지 가중치)가 연결 노드의 배열 값보다 작은 경우에는 큐에 추가한다.
7. 큐가 빌 때까지 5-6번 과정을 반복한다.
조건식을 애초에 다음과 같이 정의했기 때문에 dist[next.vertex] 값은 항상 최단 거리를 유지하며 갱신한다. 그리고 더 작은 값을 발견하게 되면 큐에 중복된 노드가 들어갈 수 있다. 어차피 우선순위 큐이기 때문에 더 작은 값을 먼저 처리하게 되고, 이후의 Node는 두 번째 조건식에 의해 막힌다. 따라서 아직 처리되지 않은 노드라면 큐에 여러 번 들어갈 수 있다.
if (!visited[next.vertex] && dist[cur.vertex] + next.weight < dist[next.vertex]) {
if(visited[cur.vertex]) continue;- 코드
코드는 두 개의 빈출 문제로 살펴본다.
1. 최단 경로 구하기 (백준 1753)
이 문제는 일반적으로 출발 노드에서 다른 모든 노드까지 최단 거리가 얼마인지를 구하는 문제다. 경로는 추적하지 않는다.
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.PriorityQueue;
import java.util.Queue;
import java.util.StringTokenizer;
public class Main {
static ArrayList<Node>[] graph;
static boolean[] visited;
static int[] dist;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int V = Integer.parseInt(st.nextToken()); // 정점 개수 (정점은 1~V)
int E = Integer.parseInt(st.nextToken()); // 간선 개수
int K = Integer.parseInt(br.readLine()); // 시작 정점
graph = new ArrayList[V + 1];
for (int i = 1; i <= V; i++) {
graph[i] = new ArrayList<>();
}
dist = new int[V + 1];
Arrays.fill(dist, Integer.MAX_VALUE);
visited = new boolean[V + 1];
while (E-- > 0) {
st = new StringTokenizer(br.readLine());
int u = Integer.parseInt(st.nextToken());
int v = Integer.parseInt(st.nextToken());
int w = Integer.parseInt(st.nextToken());
graph[u].add(new Node(v, w)); // u에서 v까지 w만큼 걸린다
}
dist[K] = 0;
Queue<Node> queue = new PriorityQueue<>();
queue.add(new Node(K, 0));
while(!queue.isEmpty()) {
Node cur = queue.poll();
if(visited[cur.vertex]) continue;
visited[cur.vertex] = true;
for (Node next : graph[cur.vertex]) {
if (!visited[next.vertex] && dist[cur.vertex] + next.weight < dist[next.vertex]) {
dist[next.vertex] = dist[cur.vertex] + next.weight;
queue.add(new Node(next.vertex, dist[next.vertex]));
}
}
}
for (int i = 1; i <= V; i++) {
if (dist[i] == Integer.MAX_VALUE) {
bw.write("INF\n");
continue;
}
bw.write(dist[i] + "\n");
}
bw.flush();
bw.close();
br.close();
}
static class Node implements Comparable<Node> {
int vertex; // 정점
int weight; // 가중치
public Node(int vertex, int weight) {
this.vertex = vertex;
this.weight = weight;
}
@Override
public int compareTo(Node o) {
return this.weight - o.weight; // 오름차순 정렬, 우리는 맨 앞의 가장 작은 노드를 선택
}
}
}
2. k번째 최단 경로 찾기 (백준 1854)
문제 자체는 직관적인 편이다. 일반적인 다익스트라 알고리즘이 최단 경로 인 값을 구했다면, 이번에는 k번째로 짧은 경로의 값을 구하는 것이다. (코드는 하루코딩님(@doitcoding) 코드 참고했습니다.)

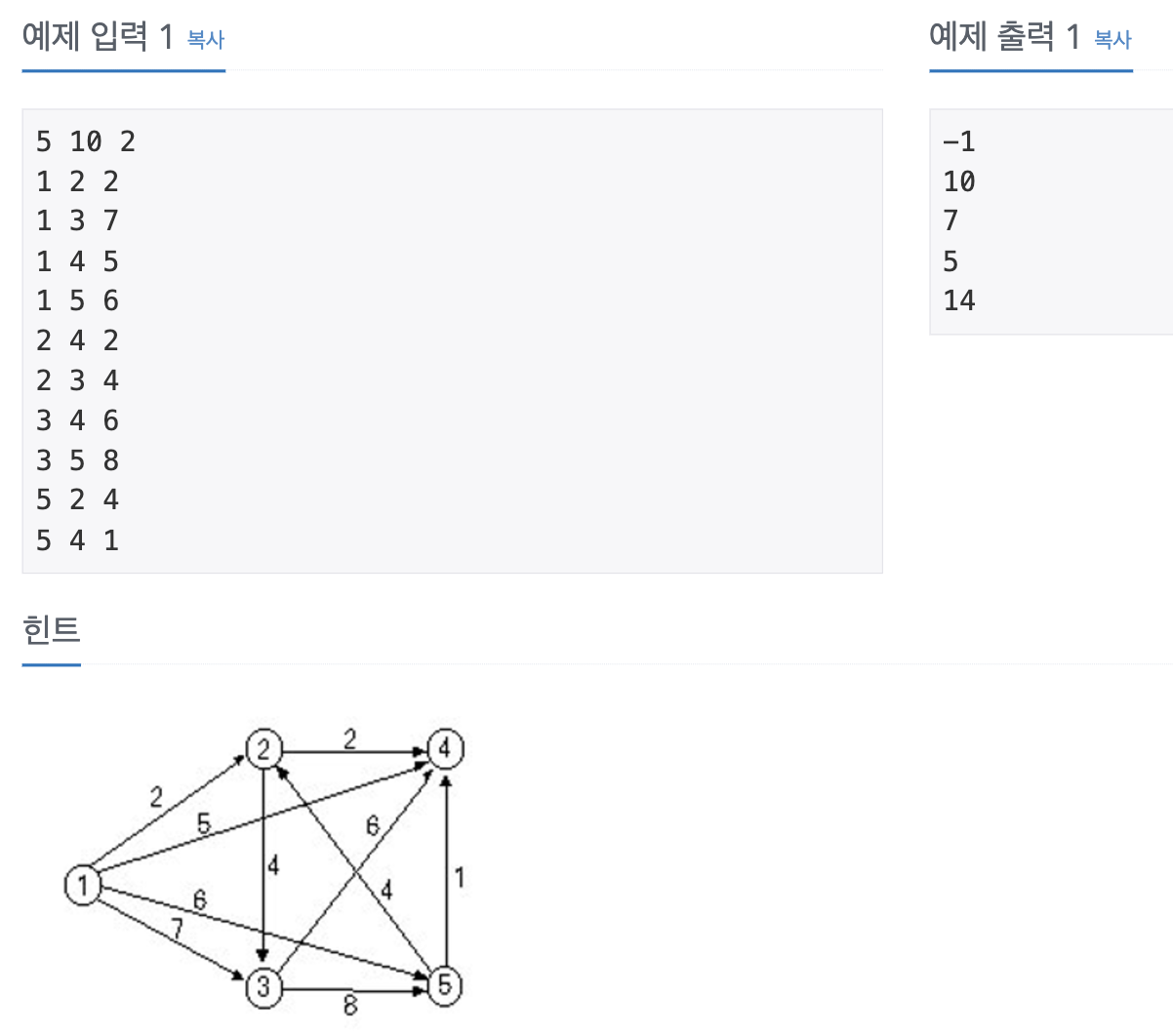
우선적으로 문제는 이런 식으로 "판단"해야 한다. 높은 난이도 때문에 자주 핵심은 파악하지 못 하고 복잡한 곳부터 생각하게 되지만 이 방법을 왜 써야 하는지를 명확하게 알고 넘어가야 비슷한 문제에서도 차근차근 접근해서 풀 수 있을 것이다.
k번째
k번째 -> 값이 k개, 순서(정렬)
k개의 값을 저장할 필요가 있고, 그 순서를 정렬할 필요가 있음
priority_queue(heap)
일반적인 최단경로(다익스트라) - 최소비용
필요한 값(저장해야 하는 값) 1개 뿐 - 최단경로의 값
visit dp dist 값을 저장하고 갱신함
출처 https://www.youtube.com/watch?v=ocWW7sXucQA
책의 코드(@doitcoding)에서는 그래프를 인접 행렬로 풀었다. 그 동안 인접 리스트로만 봤더니 정작 인접 행렬을 잘 몰라서 처음에 당황했고, 우선순위 큐 배열이라 하니 머릿속으로 어떤 형태인지 바로 안 그려져서 코드 해석하는 데 오래 걸렸다. 여기는 distQueue라는 우선순위 큐 배열(내림차순)을 사용했다. 전체 로직은 어떤 노드에 대해 갱신된 경로의 값을 리스트 형태로 저장해서 배열의 크기와 맨 앞에 위치한 수를 확인하는 형태다. 예를 들어 k=3일 때 1번 노드에 대한 경로가 그동안 2번 바뀌었다면(= 배열 크기가 2) 나중에 다른 경로가 또 존재할 때 바로 삽입하면 된다. 그때는 배열의 크기가 3이 되면서 k와 같아지는데, 이때 PriorityQueue의 맨 앞에 위치한 수가 답이 된다. (-> 4, 2, 1에서 4는 3번째로 작은 수다.) 그런데 여기서 또 다른 경로가 추가로 존재한다면, 맨 위의 수, 즉 여기서는 4를 보고 값을 비교한다. 추가 경로의 값이 3이면 4와 비교했을 때 더 작은 수니까 4를 제거하고 3을 추가한다. (-> 전체 경우의 수 중에 3번째로 작은 수를 찾는 거니까 더 큰 수를 뺀다. 그러면 삽입된 3은 전체 값들 중 3번째로 작은 수가 된다.) 그리고 당연스럽게도 가능한 경로가 k개 미만으로 존재할 경우 k번째의 경로는 없는 것이다.
인접 행렬과 인접 리스트의 차이를 알고 문제에 따라 어떤 방식이 더 좋을지 판단하여 사용해야 한다.
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.Collections;
import java.util.PriorityQueue;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
int N, M, K;
int[][] W = new int[1001][1001]; // 인접 행렬
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken());
M = Integer.parseInt(st.nextToken());
K = Integer.parseInt(st.nextToken());
PriorityQueue<Integer>[] distQueue = new PriorityQueue[N + 1];
for (int i = 0; i < N + 1; i++) { // 각 원소에 우선 순위 큐 생성
distQueue[i] = new PriorityQueue<Integer>(K, Collections.reverseOrder());
}
for (int i = 0; i < M; i++) { // 인접 행렬에 그래프 데이터 저장
st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
int c = Integer.parseInt(st.nextToken());
W[a][b] = c;
}
PriorityQueue<Node> pq = new PriorityQueue<>(); // 가까운 노드 먼저 선택
pq.add(new Node(1, 0));
distQueue[1].add(0);
while (!pq.isEmpty()) {
int now = pq.peek().vertex;
int weight = pq.peek().weight;
pq.poll();
for (int next = 1; next <= N; next++) {
if (W[now][next] != 0) { // 연결된 모든 노드에 대하여 검색하기 (시간복잡도 측면에서 인접행렬이 불리한이유)
if (distQueue[next].size() < K) { // 저장된 경로가 k개보다 작다면
distQueue[next].add(W[now][next] + weight); // 바로 추가
pq.add(new Node(next, W[now][next] + weight));
}
else if (distQueue[next].peek() > W[now][next] + weight) { // 저장된 경로가 K개면서 값이 top보다 작을 때
distQueue[next].poll(); // 기존 큐에서 가장 큰 값을 제거
distQueue[next].add(W[now][next] + weight); // 제거한 값보다 작은 값을 삽입
pq.add(new Node(next, W[now][next] + weight));
}
}
// W[now][next] == 0이면 인접 노드가 없다는 뜻
}
}
for (int i = 1; i <= N; i++) { // K번째 경로 출력
if (distQueue[i].size() == K) {
bw.write(distQueue[i].peek() + "\n");
} else {
bw.write(-1 + "\n");
}
}
bw.flush();
bw.close();
br.close();
}
// 최소 힙
static class Node implements Comparable<Node> {
int vertex;
int weight;
Node(int vertex, int weight) {
this.vertex = vertex;
this.weight = weight;
}
@Override
public int compareTo(Node o) {
return this.weight - o.weight; // 오름차순
}
}
}
참고 풀이
- https://velog.io/@rootachieve/백준-1854-k번째-최단경로-찾기
- https://www.youtube.com/watch?v=ocWW7sXucQA
참고 사이트
- https://www.geeksforgeeks.org/dijkstras-shortest-path-algorithm-greedy-algo-7/
'문제 및 이론 정리 > Algorithm' 카테고리의 다른 글
| [알고리즘] 그래프 탐색 알고리즘 - DFS, BFS (5) | 2024.10.17 |
|---|---|
| [알고리즘] 병합 정렬(MergeSort) 핵심 아이디어 (1) | 2024.09.28 |
| [알고리즘] 정렬 알고리즘 - QuickSort(퀵 정렬) (2) | 2024.09.03 |
| [알고리즘] 조합과 동적 계획법 (dynamic programming) (1) | 2024.08.20 |
| [알고리즘] 등차수열의 합과 이진 탐색(Binary Search) (0) | 2024.08.18 |